Học sâu đã trở thành một từ thông dụng trong những ngày gần đây trong lĩnh vực Trí tuệ nhân tạo (AI). Trong nhiều năm, chúng tôi đã sử dụng Máy học (ML) để truyền trí thông minh cho máy móc. Trong những ngày gần đây, học sâu đã trở nên phổ biến hơn do tính ưu việt của nó trong các dự đoán so với các kỹ thuật ML truyền thống.
Học sâu về cơ bản có nghĩa là đào tạo Mạng nơ-ron nhân tạo (ANN) với lượng dữ liệu khổng lồ. Trong học sâu, mạng tự học và do đó yêu cầu dữ liệu khổng lồ để học. Trong khi học máy truyền thống về cơ bản là một tập hợp các thuật toán phân tích dữ liệu và học hỏi từ nó. Sau đó, họ sử dụng kiến thức này để đưa ra quyết định thông minh.
Bây giờ, đến với Keras, đây là một API mạng thần kinh cấp cao chạy trên TensorFlow – một nền tảng học máy mã nguồn mở đầu cuối. Sử dụng Keras, bạn dễ dàng xác định các kiến trúc ANN phức tạp để thử nghiệm trên dữ liệu lớn của mình. Máy ảnh cũng hỗ trợ GPU, điều này trở nên cần thiết để xử lý lượng dữ liệu khổng lồ và phát triển các mô hình máy học.
Trong hướng dẫn này, bạn sẽ tìm hiểu cách sử dụng Keras trong việc xây dựng mạng lưới thần kinh sâu. Chúng ta sẽ xem xét các ví dụ thực tế để giảng dạy. Vấn đề hiện tại là nhận dạng các chữ số viết tay bằng cách sử dụng mạng thần kinh được đào tạo bằng cách học sâu. Để giúp bạn hào hứng hơn với deep learning, dưới đây là ảnh chụp màn hình về các xu hướng của Google về deep learning tại đây

Như bạn có thể thấy từ sơ đồ, mối quan tâm đến học sâu đang tăng lên đều đặn trong vài năm qua. Có nhiều lĩnh vực như thị giác máy tính, xử lý ngôn ngữ tự nhiên, nhận dạng giọng nói, tin sinh học, thiết kế thuốc, v.v., nơi học sâu đã được áp dụng thành công. Hướng dẫn này sẽ giúp bạn nhanh chóng bắt đầu học sâu. Vì vậy, hãy tiếp tục đọc
Deep Learning – Học sâu
Như đã nói ở phần giới thiệu, học sâu là một quá trình đào tạo một mạng lưới thần kinh nhân tạo với một lượng dữ liệu khổng lồ. Sau khi được đào tạo, mạng sẽ có thể cung cấp cho chúng tôi dự đoán về dữ liệu chưa xem. Trước khi tôi đi sâu hơn vào việc giải thích deep learning là gì, chúng ta hãy nhanh chóng lướt qua một số thuật ngữ được sử dụng trong đào tạo mạng lưới thần kinh.
Mạng thần kinh
Ý tưởng về mạng thần kinh nhân tạo bắt nguồn từ mạng thần kinh trong não của chúng ta. Một mạng thần kinh điển hình bao gồm ba lớp — lớp đầu vào, đầu ra và lớp ẩn như trong hình bên dưới.

Đây còn được gọi là mạng nơ-ron nông , vì nó chỉ chứa một lớp ẩn. Bạn thêm nhiều lớp ẩn trong kiến trúc trên để tạo ra một kiến trúc phức tạp hơn.
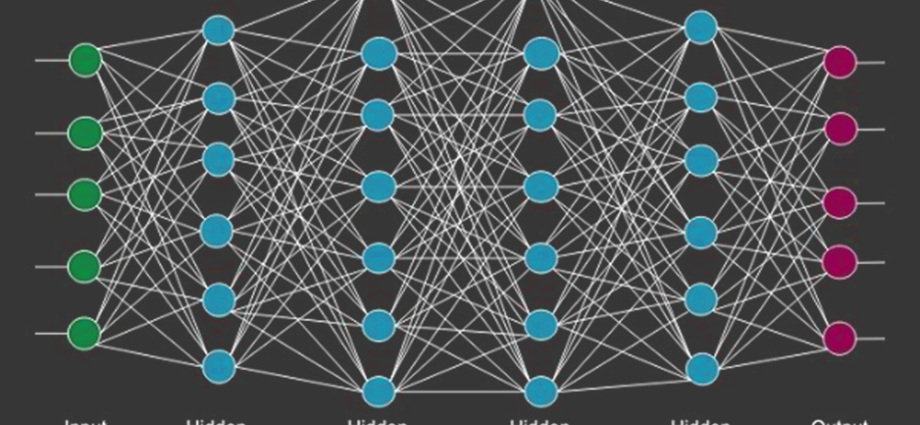
Mạng sâu
Sơ đồ sau đây cho thấy một mạng sâu bao gồm bốn lớp ẩn, lớp đầu vào và lớp đầu ra

Khi số lượng các lớp ẩn được thêm vào mạng, việc đào tạo của nó trở nên phức tạp hơn về các tài nguyên cần thiết và thời gian cần thiết để đào tạo đầy đủ mạng.
Đào tạo mạng
Sau khi bạn xác định kiến trúc mạng, bạn huấn luyện nó để thực hiện một số loại dự đoán nhất định. Đào tạo một mạng là một quá trình tìm kiếm các trọng số thích hợp cho mỗi liên kết trong mạng. Trong quá trình đào tạo, dữ liệu chuyển từ các lớp Đầu vào sang Đầu ra thông qua các lớp ẩn khác nhau. Vì dữ liệu luôn di chuyển theo một hướng từ đầu vào đến đầu ra, chúng tôi gọi mạng này là Mạng chuyển tiếp nguồn cấp dữ liệu và chúng tôi gọi quá trình truyền dữ liệu là Truyền bá chuyển tiếp.
Chức năng kích hoạt
Ở mỗi lớp, chúng tôi tính tổng trọng số của đầu vào và đưa nó vào chức năng Kích hoạt. Chức năng kích hoạt mang lại sự phi tuyến tính cho mạng. Nó chỉ đơn giản là một số hàm toán học rời rạc hóa đầu ra. Một số hàm kích hoạt được sử dụng phổ biến nhất là sigmoid, hyperbolic, tangent (tanh), ReLU và Softmax.
Lan truyền ngược
Backpropagation là một thuật toán học có giám sát. Trong Backpropagation, các lỗi lan truyền ngược từ đầu ra đến lớp đầu vào. Đưa ra một hàm lỗi, chúng tôi tính toán độ dốc của hàm lỗi đối với các trọng số được chỉ định tại mỗi kết nối. Việc tính toán độ dốc tiến hành ngược thông qua mạng. Độ dốc của lớp trọng số cuối cùng được tính trước và độ dốc của lớp trọng số đầu tiên được tính sau cùng.
Tại mỗi lớp, các tính toán từng phần của gradient được sử dụng lại trong tính toán gradient cho lớp trước đó. Điều này được gọi là Gradient Descent.
Trong hướng dẫn dựa trên dự án này, bạn sẽ xác định một mạng nơ-ron sâu chuyển tiếp nguồn cấp dữ liệu và đào tạo nó bằng các kỹ thuật lan truyền ngược và giảm dần độ dốc. May mắn thay, Keras cung cấp cho chúng tôi tất cả các API cấp cao để xác định kiến trúc mạng và đào tạo nó bằng cách sử dụng độ dốc giảm dần. Tiếp theo, bạn sẽ học cách thực hiện việc này trong Keras.
Hệ thống nhận dạng chữ số viết tay
Trong dự án nhỏ này, bạn sẽ áp dụng các kỹ thuật được mô tả trước đó. Bạn sẽ tạo một mạng thần kinh học sâu sẽ được đào tạo để nhận dạng các chữ số viết tay. Trong bất kỳ dự án học máy nào, thách thức đầu tiên là thu thập dữ liệu. Đặc biệt, đối với các mạng học sâu, bạn cần dữ liệu khổng lồ. May mắn thay, đối với vấn đề mà chúng tôi đang cố gắng giải quyết, ai đó đã tạo tập dữ liệu để đào tạo. Cái này được gọi là mnist, có sẵn như là một phần của thư viện Keras. Bộ dữ liệu bao gồm một số hình ảnh 28×28 pixel của các chữ số viết tay. Bạn sẽ đào tạo mô hình của mình trên phần chính của tập dữ liệu này và phần còn lại của dữ liệu sẽ được sử dụng để xác thực mô hình được đào tạo của bạn.
mô tả dự án
Bộ dữ liệu mnist bao gồm 70000 hình ảnh của các chữ số viết tay. Một vài hình ảnh mẫu được sao chép ở đây để bạn tham khảo

Mỗi hình ảnh có kích thước 28 x 28 pixel, tạo thành tổng số 768 pixel ở các mức thang độ xám khác nhau. Hầu hết các pixel có xu hướng về màu đen trong khi chỉ một số ít trong số chúng có màu trắng. Chúng tôi sẽ đặt phân phối của các pixel này trong một mảng hoặc một vectơ. Ví dụ: sự phân bố pixel cho một hình ảnh điển hình gồm các chữ số 4 và 5 được hiển thị trong hình bên dưới. Mỗi hình ảnh có kích thước 28 x 28 pixel, tạo thành tổng số 768 pixel ở các mức thang độ xám khác nhau. Hầu hết các pixel có xu hướng về màu đen trong khi chỉ một số ít trong số chúng có màu trắng. Chúng tôi sẽ đặt phân phối của các pixel này trong một mảng hoặc một vectơ. Ví dụ: sự phân bố pixel cho một hình ảnh điển hình gồm các chữ số 4 và 5 được hiển thị trong hình bên dưới.

Rõ ràng, bạn có thể thấy rằng sự phân bố của các pixel (đặc biệt là những pixel có xu hướng tông màu trắng) khác nhau, điều này giúp phân biệt các chữ số mà chúng đại diện. Chúng tôi sẽ cung cấp phân phối 784 pixel này cho mạng của chúng tôi làm đầu vào. Đầu ra của mạng sẽ bao gồm 10 danh mục đại diện cho một chữ số từ 0 đến 9.
Mạng của chúng tôi sẽ bao gồm 4 lớp — một lớp đầu vào, một lớp đầu ra và hai lớp ẩn. Mỗi lớp ẩn sẽ chứa 512 nút. Mỗi lớp được kết nối đầy đủ với lớp tiếp theo. Khi chúng tôi đào tạo mạng, chúng tôi sẽ tính toán trọng số cho mỗi kết nối. Chúng tôi đào tạo mạng bằng cách áp dụng lan truyền ngược và giảm dần độ dốc mà chúng tôi đã thảo luận trước đó.
Xem thêm : Deep Learning – Thiết lập dự án