Ma trận nhầm lẫn – một bảng có đầu ra được dự đoán so với đầu ra dự kiến là cách dễ nhất để đo lường hiệu suất của một vấn đề phân loại, trong đó đầu ra có thể thuộc hai loại lớp trở lên.
Như chúng ta có thể thấy, ma trận nhầm lẫn mẫu ở trên chứa 2 cột, một cột dành cho gian lận lớp và cột còn lại dành cho lớp bình thường. Tương tự như vậy, chúng ta có 2 hàng, một hàng được thêm vào cho lớp gian lận và một hàng được thêm vào cho lớp bình thường. Sau đây là giải thích về các thuật ngữ liên quan đến ma trận nhầm lẫn –
- Giá trị tích cực thực sự − Khi cả lớp thực tế & lớp điểm dữ liệu được dự đoán là 1.
- Phủ định thực sự − Khi cả lớp thực tế & lớp điểm dữ liệu được dự đoán là 0.
- Dương tính giả − Khi lớp điểm dữ liệu thực tế là 0 & lớp điểm dữ liệu được dự đoán là 1.
- Phủ định sai − Khi lớp điểm dữ liệu thực tế là 1 & lớp điểm dữ liệu được dự đoán là 0.
Hãy xem cách chúng ta có thể tính toán số lượng những thứ khác nhau từ ma trận nhầm lẫn – Độ chính xác − Đó là số lượng dự đoán đúng do mô hình phân loại ML của chúng tôi đưa ra. Nó có thể được tính bằng công thức sau

Độ chính xác −Nó cho chúng tôi biết có bao nhiêu mẫu được dự đoán chính xác trong số tất cả các mẫu mà chúng tôi dự đoán. Nó có thể được tính toán với sự trợ giúp của công thức sau –

Thu hồi hoặc Độ nhạy − Thu hồi là số lượng kết quả dương tính được mô hình phân loại ML của chúng tôi trả về. Nói cách khác, nó cho chúng ta biết có bao nhiêu trường hợp gian lận trong tập dữ liệu đã được mô hình thực sự phát hiện. Nó có thể được tính bằng công thức sau

Tính đặc hiệu − Ngược lại với việc thu hồi, nó đưa ra số lượng âm bản được mô hình phân loại ML của chúng tôi trả về. Nó có thể được tính bằng công thức sau

thước đo F
Chúng ta có thể sử dụng thước đo F thay thế cho ma trận nhầm lẫn. Lý do chính đằng sau điều này là chúng tôi không thể tối đa hóa Thu hồi và Độ chính xác cùng một lúc. Có mối quan hệ rất chặt chẽ giữa các số liệu này và có thể hiểu được điều đó nhờ sự trợ giúp của ví dụ sau –
Giả sử chúng ta muốn sử dụng mô hình DL để phân loại các mẫu tế bào là ung thư hay bình thường. Ở đây, để đạt được độ chính xác tối đa, chúng ta cần giảm số lượng dự đoán xuống còn 1. Mặc dù điều này có thể mang lại cho chúng ta độ chính xác khoảng 100%, nhưng khả năng thu hồi sẽ trở nên rất thấp.
Mặt khác, nếu muốn đạt mức thu hồi tối đa, chúng ta cần đưa ra càng nhiều dự đoán càng tốt. Mặc dù điều này có thể giúp chúng tôi đạt được khoảng 100% thu hồi, nhưng độ chính xác sẽ trở nên rất thấp. Trong thực tế, chúng ta cần tìm cách cân bằng giữa độ chính xác và khả năng thu hồi. Số liệu đo F cho phép chúng tôi làm như vậy vì nó biểu thị mức trung bình hài hòa giữa độ chính xác và khả năng thu hồi.

Công thức này được gọi là thước đo F1, trong đó thuật ngữ bổ sung có tên B được đặt thành 1 để có tỷ lệ chính xác và thu hồi bằng nhau. Để nhấn mạnh khả năng thu hồi, chúng ta có thể đặt hệ số B thành 2. Mặt khác, để nhấn mạnh độ chính xác, chúng ta có thể đặt hệ số B thành 0,5.
Sử dụng CNTK để đo hiệu suất phân loại
Trong phần trước, chúng tôi đã tạo một mô hình phân loại bằng cách sử dụng tập dữ liệu hoa Iris. Ở đây, chúng tôi sẽ đo lường hiệu suất của nó bằng cách sử dụng ma trận nhầm lẫn và thước đo F.
Tạo ma trận nhầm lẫn
Chúng tôi đã tạo mô hình nên có thể bắt đầu quá trình xác thực, bao gồm ma trận nhầm lẫn, trên cùng một mô hình. Đầu tiên, chúng ta sẽ tạo ma trận nhầm lẫn với sự trợ giúp của hàm confusion_matrix từ scikit-learn. Để làm được điều này, chúng tôi cần nhãn thực cho các mẫu thử nghiệm của mình và nhãn dự đoán cho cùng một mẫu thử nghiệm. Hãy tính ma trận nhầm lẫn bằng cách sử dụng mã python sau
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)
đầu ra
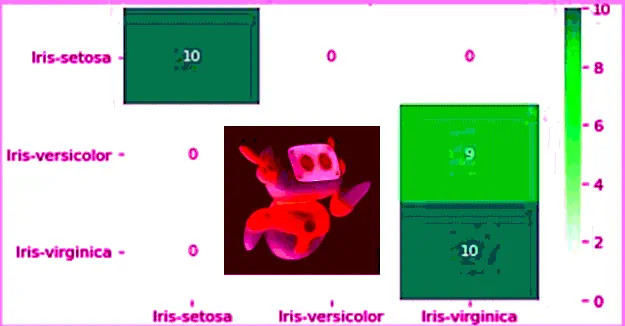
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]
Chúng ta cũng có thể sử dụng chức năng bản đồ nhiệt để trực quan hóa ma trận nhầm lẫn như sau
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()

Chúng ta cũng nên có một con số hiệu suất duy nhất mà chúng ta có thể sử dụng để so sánh mô hình. Để làm điều này, chúng ta cần tính toán lỗi phân loại bằng cách sử dụng hàm classification_error, từ gói số liệu trong CNTK như đã thực hiện khi tạo mô hình phân loại. Bây giờ để tính toán lỗi phân loại, hãy thực hiện phương pháp kiểm tra hàm mất mát bằng một tập dữ liệu. Sau đó, CNTK sẽ lấy các mẫu mà chúng tôi cung cấp làm đầu vào cho chức năng này và đưa ra dự đoán dựa trên các tính năng đầu vào X_test.
loss.test([X_test, y_test])đầu ra :
{'metric': 0.36666666666, 'samples': 30}Thực hiện các biện pháp F
Để triển khai F-Measures, CNTK cũng bao gồm chức năng gọi là fmeasures. Chúng ta có thể sử dụng hàm này trong khi huấn luyện NN bằng cách thay thế ô cntk.metrics.classification_error bằng lệnh gọi tới cntk.losses.fmeasure khi xác định hàm nhà máy tiêu chí như sau
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metric
Sau khi sử dụng hàm cntk.losses.fmeasure, chúng ta sẽ nhận được kết quả đầu ra khác nhau cho lệnh gọi phương thức loss.test như sau
loss.test([X_test, y_test])đầu ra:
{'metric': 0.83101488749, 'samples': 30}Xem thêm : CNTK – Mô hình hồi quy