Kỹ thuật phân loại hoặc mô hình cố gắng đưa ra một số kết luận từ các giá trị được quan sát. Trong bài toán phân loại, chúng ta có đầu ra được phân loại như “Đen” hoặc “trắng” hoặc “Dạy” và “Không dạy”. Trong khi xây dựng mô hình phân loại, chúng ta cần có tập dữ liệu huấn luyện chứa các điểm dữ liệu và các nhãn tương ứng. Ví dụ: nếu chúng tôi muốn kiểm tra xem hình ảnh có phải là ô tô hay không. Để kiểm tra điều này, chúng ta sẽ xây dựng tập dữ liệu huấn luyện có hai lớp liên quan đến “car” và “no car”. Sau đó, chúng ta cần đào tạo mô hình bằng cách sử dụng các mẫu đào tạo. Các mô hình phân loại chủ yếu được sử dụng trong nhận dạng khuôn mặt, nhận dạng thư rác, v.v.
Các bước để xây dựng Trình phân loại trong Python
Để xây dựng bộ phân loại trong Python, chúng tôi sẽ sử dụng Python 3 và Scikit-learning, một công cụ dành cho máy học. Thực hiện theo các bước sau để xây dựng bộ phân loại trong Python −
Bước 1 – Nhập Scikit-learning
Đây sẽ là bước đầu tiên để xây dựng bộ phân loại trong Python. Trong bước này, chúng tôi sẽ cài đặt gói Python có tên Scikit-learn, đây là một trong những mô-đun máy học tốt nhất trong Python. Lệnh sau sẽ giúp chúng tôi nhập gói –
Import Sklearn
Bước 2 – Nhập tập dữ liệu của Scikit-learn
Trong bước này, chúng ta có thể bắt đầu làm việc với tập dữ liệu cho mô hình học máy của mình. Ở đây, chúng tôi sẽ sử dụng Cơ sở dữ liệu chẩn đoán. Bộ dữ liệu bao gồm nhiều thông tin khác nhau, cũng như nhãn phân. Bộ dữ liệu có 569 phiên bản hoặc dữ liệu về 569 và bao gồm thông tin về 30 thuộc tính hoặc tính năng, chẳng hạn như bán kính của khối, kết cấu, độ mịn và diện tích. Với sự trợ giúp của lệnh sau, chúng ta có thể nhập bộ dữ liệu của Scikit-learn –
from sklearn.datasets import load_breast_cancer
Bây giờ, lệnh sau sẽ tải tập dữ liệu.
data = load_breast_cancer()
Sau đây là danh sách các khóa từ điển quan trọng –
- Tên nhãn phân loại (tên_mục tiêu)
- Các nhãn thực tế (mục tiêu)
- Tên thuộc tính/tính năng (feature_names)
- Thuộc tính (dữ liệu)
Bây giờ, với sự trợ giúp của lệnh sau, chúng ta có thể tạo các biến mới cho từng bộ thông tin quan trọng và gán dữ liệu. Nói cách khác, chúng ta có thể sắp xếp dữ liệu bằng các lệnh sau
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
Bây giờ, để rõ ràng hơn, chúng ta có thể in nhãn lớp, nhãn của đối tượng dữ liệu đầu tiên, tên đối tượng và giá trị của đối tượng với sự trợ giúp của các lệnh sau –
print(label_names)
Lệnh trên sẽ in tên lớp tương ứng là ác tính và lành tính. Nó được hiển thị như đầu ra bên dưới –
['malignant' 'benign']
Bây giờ, lệnh bên dưới sẽ hiển thị rằng chúng được ánh xạ tới các giá trị nhị phân 0 và 1. Ở đây 0 đại diện cho ung thư ác tính và 1 đại diện cho ung thư lành tính. Bạn sẽ nhận được đầu ra sau –
print(labels[0])
0Hai lệnh được đưa ra dưới đây sẽ tạo ra các tên tính năng và giá trị tính năng.
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
Từ đầu ra ở trên, chúng ta có thể thấy rằng phiên bản dữ liệu đầu tiên là một khối u ác tính có bán kính là 1,7990000e+01.
Bước 3 – Sắp xếp dữ liệu thành các tập hợp
Trong bước này, chúng tôi sẽ chia dữ liệu của mình thành hai phần là tập huấn luyện và tập kiểm tra. Việc chia dữ liệu thành các tập hợp này là rất quan trọng vì chúng tôi phải kiểm tra mô hình của mình trên dữ liệu không nhìn thấy được. Để chia dữ liệu thành các tập hợp, sklearn có một hàm gọi là hàm train_test_split() . Với sự trợ giúp của các lệnh sau, chúng ta có thể chia dữ liệu trong các bộ này –
from sklearn.model_selection import train_test_split
Lệnh trên sẽ nhập hàm train_test_split từ sklearn và lệnh bên dưới sẽ chia dữ liệu thành dữ liệu huấn luyện và kiểm tra. Trong ví dụ được đưa ra dưới đây, chúng tôi đang sử dụng 40% dữ liệu để thử nghiệm và dữ liệu còn lại sẽ được sử dụng để huấn luyện mô hình
train, test, train_labels, test_labels = train_test_split(features,labels,test_size = 0.40, random_state = 42)Bước 4 – Xây dựng mô hình
Trong bước này, chúng tôi sẽ xây dựng mô hình của chúng tôi. Chúng tôi sẽ sử dụng thuật toán Naïve Bayes để xây dựng mô hình. Các lệnh sau có thể được sử dụng để xây dựng mô hình –
from sklearn.naive_bayes import GaussianNB
Lệnh trên sẽ nhập mô-đun GaussianNB. Bây giờ, lệnh sau sẽ giúp bạn khởi tạo mô hình.
gnb = GaussianNB()
Chúng tôi sẽ đào tạo mô hình bằng cách khớp nó với dữ liệu bằng cách sử dụng gnb.fit().
model = gnb.fit(train, train_labels)
Bước 5 – Đánh giá mô hình và độ chính xác của nó
Trong bước này, chúng tôi sẽ đánh giá mô hình bằng cách đưa ra dự đoán về dữ liệu thử nghiệm của chúng tôi. Sau đó, chúng tôi cũng sẽ tìm ra độ chính xác của nó. Để đưa ra dự đoán, chúng ta sẽ sử dụng hàm predict(). Lệnh sau sẽ giúp bạn làm điều này
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
Chuỗi số 0 và 1 ở trên là các giá trị dự đoán cho các loại. Bây giờ, bằng cách so sánh hai mảng là test_labels và preds , chúng ta có thể tìm ra độ chính xác của mô hình của mình. Chúng ta sẽ sử dụng hàm precision_score() để xác định độ chính xác. Hãy xem xét lệnh sau cho điều này
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965
Kết quả cho thấy bộ phân loại NaïveBayes có độ chính xác 95,17%.
Bằng cách này, với sự trợ giúp của các bước trên, chúng ta có thể xây dựng trình phân loại của mình bằng Python.
Trình phân loại tháp trong Python
Trong phần này, chúng ta sẽ tìm hiểu cách xây dựng bộ phân loại trong Python.
Bộ phân loại Naïve Bayes
Naïve Bayes là một kỹ thuật phân loại được sử dụng để xây dựng bộ phân loại sử dụng định lý Bayes. Giả định là các yếu tố dự đoán là độc lập. Nói một cách đơn giản, nó giả định rằng sự hiện diện của một tính năng cụ thể trong một lớp không liên quan đến sự hiện diện của bất kỳ tính năng nào khác. Để xây dựng trình phân loại Naïve Bayes, chúng ta cần sử dụng thư viện python có tên là scikit learn. Có ba loại mô hình Naïve Bayes có tên là Gaussian, Multinomial và Bernoulli trong gói tìm hiểu scikit.
Để xây dựng mô hình phân loại máy học Naïve Bayes, chúng ta cần & trừ
tập dữ liệu
Chúng tôi sẽ sử dụng bộ dữ liệu có tên Cơ sở dữ liệu chẩn đoán. Bộ dữ liệu bao gồm nhiều thông tin khác nhau về các khối, cũng như nhãn phân . Bộ dữ liệu có 569 phiên bản hoặc dữ liệu về 569. Chúng tôi có thể nhập tập dữ liệu này từ gói sklearn.
Người mẫu Naïve Bayes
Để xây dựng bộ phân loại Naïve Bayes, chúng ta cần một mô hình Naïve Bayes. Như đã nói trước đó, có ba loại mô hình Naïve Bayes có tên là Gaussian, Multinomial và Bernoulli trong gói tìm hiểu scikit. Ở đây, trong ví dụ sau, chúng ta sẽ sử dụng mô hình Gaussian Naïve Bayes.
Bằng cách sử dụng những điều trên, chúng ta sẽ xây dựng một mô hình máy học Naïve Bayes để sử dụng thông tin về khối u để dự đoán khối u là ác tính hay lành tính.
Để bắt đầu, chúng ta cần cài đặt mô-đun sklearn. Nó có thể được thực hiện với sự trợ giúp của lệnh sau –
Import Sklearn
Bây giờ, chúng ta cần nhập tập dữ liệu có tên Cơ sở dữ liệu chẩn đoán
from sklearn.datasets import load_breast_cancerBây giờ, lệnh sau sẽ tải tập dữ liệu.
data = load_breast_cancer()
Dữ liệu có thể được tổ chức như sau
label_names = data['target_names']
labels = data['target']
feature_names = data['feature_names']
features = data['data']
Bây giờ, để làm rõ hơn, chúng ta có thể in các nhãn lớp, nhãn của đối tượng dữ liệu đầu tiên, tên đối tượng và giá trị của đối tượng với sự trợ giúp của các lệnh sau –
print(label_names)
Lệnh trên sẽ in tên lớp tương ứng là ác tính và lành tính. Nó được hiển thị như đầu ra bên dưới –
['malignant' 'benign']
Bây giờ, lệnh đưa ra dưới đây sẽ cho thấy rằng chúng được ánh xạ tới các giá trị nhị phân 0 và 1. Ở đây 0 đại diện cho ung thư ác tính và 1 đại diện cho ung thư lành tính. Nó được hiển thị như đầu ra bên dưới
print(labels[0])
0
Hai lệnh sau sẽ tạo tên đối tượng và giá trị đối tượng.
print(feature_names[0])
mean radius
print(features[0])
[ 1.79900000e+01 1.03800000e+01 1.22800000e+02 1.00100000e+03
1.18400000e-01 2.77600000e-01 3.00100000e-01 1.47100000e-01
2.41900000e-01 7.87100000e-02 1.09500000e+00 9.05300000e-01
8.58900000e+00 1.53400000e+02 6.39900000e-03 4.90400000e-02
5.37300000e-02 1.58700000e-02 3.00300000e-02 6.19300000e-03
2.53800000e+01 1.73300000e+01 1.84600000e+02 2.01900000e+03
1.62200000e-01 6.65600000e-01 7.11900000e-01 2.65400000e-01
4.60100000e-01 1.18900000e-01]
Từ đầu ra ở trên, chúng ta có thể thấy rằng phiên bản dữ liệu đầu tiên là một khối u ác tính có bán kính chính là 1,7990000e+01.
Để thử nghiệm mô hình của chúng tôi trên dữ liệu không nhìn thấy, chúng tôi cần chia dữ liệu của mình thành dữ liệu đào tạo và thử nghiệm. Nó có thể được thực hiện với sự trợ giúp của đoạn mã sau –
from sklearn.model_selection import train_test_split
Lệnh trên sẽ nhập hàm train_test_split từ sklearn và lệnh bên dưới sẽ chia dữ liệu thành dữ liệu huấn luyện và kiểm tra. Trong ví dụ dưới đây, chúng tôi đang sử dụng 40% dữ liệu để thử nghiệm và dữ liệu khai thác lại sẽ được sử dụng để huấn luyện mô hình.
train, test, train_labels, test_labels =
train_test_split(features,labels,test_size = 0.40, random_state = 42)
Bây giờ, chúng ta đang xây dựng mô hình bằng các lệnh sau –
from sklearn.naive_bayes import GaussianNB
Lệnh trên sẽ nhập mô-đun GaussianNB . Bây giờ, với lệnh dưới đây, chúng ta cần khởi tạo mô hình
gnb = GaussianNB()
Chúng tôi sẽ đào tạo mô hình bằng cách khớp nó với dữ liệu bằng cách sử dụng gnb.fit() .
model = gnb.fit(train, train_labels)
Bây giờ, hãy đánh giá mô hình bằng cách đưa ra dự đoán trên dữ liệu thử nghiệm và nó có thể được thực hiện như sau
preds = gnb.predict(test)
print(preds)
[1 0 0 1 1 0 0 0 1 1 1 0 1 0 1 0 1 1 1 0 1 1 0 1 1 1 1 1 1
0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
0 1 1 0 0 1 1 1 0 0 1 1 0 0 1 0 1 1 1 1 1 1 0 1 1 0 0 0 0
0 1 1 1 1 1 1 1 1 0 0 1 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 0
1 1 1 0 0 1 1 0 1 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 0 1 1 0
1 0 0 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0
1 1 0 1 1 1 1 1 1 0 0 0 1 1 0 1 0 1 1 1 1 0 1 1 0 1 1 1 0
1 0 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1 1 0 1]
Chuỗi số 0 và 1 ở trên là các giá trị dự đoán cho các loại khối u tức là ác tính và lành tính. Bây giờ, bằng cách so sánh hai mảng là test_labels và preds , chúng ta có thể tìm ra độ chính xác của mô hình của mình. Chúng ta sẽ sử dụng hàm precision_score() để xác định độ chính xác. Hãy xem xét lệnh sau
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels,preds))
0.951754385965
Kết quả cho thấy bộ phân loại NaïveBayes có độ chính xác 95,17%.
Đó là bộ phân loại máy học dựa trên mô hình Naïve Bayse Gaussian.
Máy véc tơ hỗ trợ (SVM)
Về cơ bản, Máy vectơ hỗ trợ (SVM) là một thuật toán học máy được giám sát có thể được sử dụng cho cả hồi quy và phân loại. Khái niệm chính của SVM là vẽ từng mục dữ liệu dưới dạng một điểm trong không gian n chiều với giá trị của mỗi đối tượng địa lý là giá trị của một tọa độ cụ thể. Ở đây n sẽ là các tính năng chúng ta sẽ có. Sau đây là một biểu diễn đồ họa đơn giản để hiểu khái niệm về SVM
")
Trong sơ đồ trên, chúng ta có hai tính năng. Do đó, trước tiên chúng ta cần vẽ hai biến này trong không gian hai chiều trong đó mỗi điểm có hai tọa độ, được gọi là vectơ hỗ trợ. Dòng chia dữ liệu thành hai nhóm được phân loại khác nhau. Dòng này sẽ là phân loại.
Ở đây, chúng ta sẽ xây dựng một bộ phân loại SVM bằng cách sử dụng bộ dữ liệu scikit-learning và iris. Thư viện Scikitlearn có mô-đun sklearn.svm và cung cấp sklearn.svm.svc để phân loại. Bộ phân loại SVM để dự đoán lớp của cây diên vĩ dựa trên 4 đặc điểm được trình bày bên dưới.
tập dữ liệu
Chúng tôi sẽ sử dụng bộ dữ liệu iris bao gồm 3 lớp, mỗi lớp 50 trường hợp, trong đó mỗi lớp đề cập đến một loại cây iris. Mỗi cá thể có bốn đặc điểm là chiều dài đài hoa, chiều rộng đài hoa, chiều dài cánh hoa và chiều rộng cánh hoa. Bộ phân loại SVM để dự đoán lớp của cây diên vĩ dựa trên 4 đặc điểm được trình bày bên dưới.
hạt nhân
Nó là một kỹ thuật được sử dụng bởi SVM. Về cơ bản, đây là các hàm lấy không gian đầu vào có chiều thấp và biến đổi nó thành không gian có chiều cao hơn. Nó chuyển đổi vấn đề không thể tách rời thành vấn đề có thể tách rời. Hàm hạt nhân có thể là bất kỳ hàm nào trong số tuyến tính, đa thức, rbf và sigmoid. Trong ví dụ này, chúng tôi sẽ sử dụng nhân tuyến tính. Bây giờ chúng ta hãy nhập các gói sau
import pandas as pd
import numpy as np
from sklearn import svm, datasets
import matplotlib.pyplot as plt
Bây giờ, tải dữ liệu đầu vào –
iris = datasets.load_iris()
Chúng tôi đang sử dụng hai tính năng đầu tiên
X = iris.data[:, :2]
y = iris.target
Chúng tôi sẽ vẽ các ranh giới của máy vectơ hỗ trợ với dữ liệu gốc. Chúng tôi đang tạo một lưới để vẽ đồ thị.
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
h = (x_max / x_min)/100
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
X_plot = np.c_[xx.ravel(), yy.ravel()]
Chúng ta cần cung cấp giá trị của tham số chuẩn hóa.
C = 1.0
Chúng ta cần tạo đối tượng phân loại SVM.
Svc_classifier = svm_classifier.SVC(kernel='linear',
C=C, decision_function_shape = 'ovr').fit(X, y)
Z = svc_classifier.predict(X_plot)
Z = Z.reshape(xx.shape)
plt.figure(figsize = (15, 5))
plt.subplot(121)
plt.contourf(xx, yy, Z, cmap = plt.cm.tab10, alpha = 0.3)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = plt.cm.Set1)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.title('SVC with linear kernel')

Hồi quy logistic
Về cơ bản, mô hình hồi quy logistic là một trong những thành viên của họ thuật toán phân loại có giám sát. Hồi quy logistic đo lường mối quan hệ giữa các biến phụ thuộc và biến độc lập bằng cách ước tính xác suất sử dụng hàm logistic.
Ở đây, nếu chúng ta nói về các biến phụ thuộc và biến độc lập thì biến phụ thuộc là biến lớp mục tiêu mà chúng ta sẽ dự đoán và mặt khác, các biến độc lập là các tính năng chúng ta sẽ sử dụng để dự đoán lớp mục tiêu.
Trong hồi quy logistic, ước tính xác suất có nghĩa là dự đoán khả năng xảy ra sự kiện. Ví dụ, chủ cửa hàng muốn dự đoán khách hàng bước vào cửa hàng sẽ mua máy chơi game (chẳng hạn) hay không. Sẽ có nhiều đặc điểm của khách hàng – giới tính, độ tuổi, v.v. sẽ được người bán hàng quan sát để dự đoán khả năng xảy ra, tức là có mua một máy chơi game hay không. Hàm logistic là đường cong sigmoid được sử dụng để xây dựng hàm với các tham số khác nhau.
điều kiện tiên quyết
Trước khi xây dựng bộ phân loại bằng hồi quy logistic, chúng ta cần cài đặt gói Tkinter trên hệ thống của mình. Nó có thể được cài đặt từ https://docs.python.org/2/library/tkinter.html .
Bây giờ, với sự trợ giúp của đoạn mã dưới đây, chúng ta có thể tạo bộ phân loại bằng hồi quy logistic – Đầu tiên, chúng tôi sẽ nhập một số gói
import numpy as np
from sklearn import linear_model
import matplotlib.pyplot as plt
Bây giờ, chúng ta cần xác định dữ liệu mẫu có thể được thực hiện như sau
X = np.array([[2, 4.8], [2.9, 4.7], [2.5, 5], [3.2, 5.5], [6, 5], [7.6, 4],
[3.2, 0.9], [2.9, 1.9],[2.4, 3.5], [0.5, 3.4], [1, 4], [0.9, 5.9]])
y = np.array([0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3])
Tiếp theo, chúng ta cần tạo trình phân loại hồi quy logistic, có thể được thực hiện như sau
Classifier_LR = linear_model.LogisticRegression(solver = 'liblinear', C = 75)
Cuối cùng nhưng không kém phần quan trọng, chúng ta cần huấn luyện bộ phân loại này –
Classifier_LR.fit(X, y)
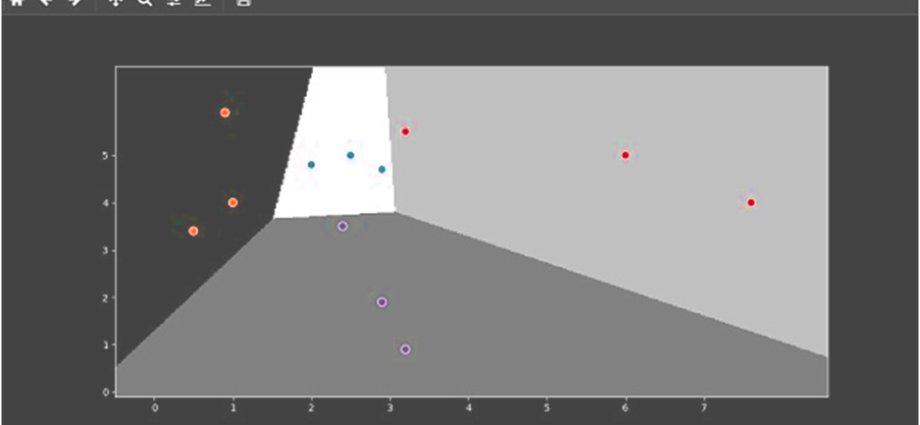
Bây giờ, làm thế nào chúng ta có thể hình dung đầu ra? Nó có thể được thực hiện bằng cách tạo một hàm có tên Logistic_visualize()
Def Logistic_visualize(Classifier_LR, X, y):
min_x, max_x = X[:, 0].min() - 1.0, X[:, 0].max() + 1.0
min_y, max_y = X[:, 1].min() - 1.0, X[:, 1].max() + 1.0
Trong dòng trên, chúng tôi đã xác định các giá trị tối thiểu và tối đa X và Y sẽ được sử dụng trong lưới lưới. Ngoài ra, chúng tôi sẽ xác định kích thước bước để vẽ sơ đồ lưới mắt lưới.
mesh_step_size = 0.02
Hãy để chúng tôi xác định lưới lưới của các giá trị X và Y như sau
x_vals, y_vals = np.meshgrid(np.arange(min_x, max_x, mesh_step_size),
np.arange(min_y, max_y, mesh_step_size))
Với sự trợ giúp của đoạn mã sau, chúng ta có thể chạy trình phân loại trên lưới mesh
output = classifier.predict(np.c_[x_vals.ravel(), y_vals.ravel()])
output = output.reshape(x_vals.shape)
plt.figure()
plt.pcolormesh(x_vals, y_vals, output, cmap = plt.cm.gray)
plt.scatter(X[:, 0], X[:, 1], c = y, s = 75, edgecolors = 'black',
linewidth=1, cmap = plt.cm.Paired)
Dòng mã sau sẽ chỉ định ranh giới
plt.xlim(x_vals.min(), x_vals.max())
plt.ylim(y_vals.min(), y_vals.max())
plt.xticks((np.arange(int(X[:, 0].min() - 1), int(X[:, 0].max() + 1), 1.0)))
plt.yticks((np.arange(int(X[:, 1].min() - 1), int(X[:, 1].max() + 1), 1.0)))
plt.show()
Bây giờ, sau khi chạy mã, chúng ta sẽ nhận được đầu ra sau, bộ phân loại hồi quy logistic

Trình phân loại cây quyết định
Cây quyết định về cơ bản là một sơ đồ cây nhị phân trong đó mỗi nút phân chia một nhóm các quan sát theo một số biến đặc trưng.
Ở đây, chúng tôi đang xây dựng bộ phân loại Cây quyết định để dự đoán nam hay nữ. Chúng tôi sẽ lấy một tập dữ liệu rất nhỏ có 19 mẫu. Những mẫu này sẽ bao gồm hai đặc điểm – ‘chiều cao’ và ‘độ dài của tóc’.
Điều kiện tiên quyết
Để xây dựng bộ phân loại sau, chúng ta cần cài đặt pydotplus và graphviz . Về cơ bản, graphviz là một công cụ để vẽ đồ họa bằng các tệp dấu chấm và pydotplus là một mô-đun cho ngôn ngữ Dot của Graphviz. Nó có thể được cài đặt với trình quản lý gói hoặc pip.
Bây giờ, chúng ta có thể xây dựng trình phân loại cây quyết định với sự trợ giúp của mã Python sau – Để bắt đầu, chúng ta hãy nhập một số thư viện quan trọng như sau
import pydotplus
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.metrics import classification_report
from sklearn import cross_validation
import collections
Bây giờ, chúng ta cần cung cấp tập dữ liệu như sau
X = [[165,19],[175,32],[136,35],[174,65],[141,28],[176,15],[131,32],
[166,6],[128,32],[179,10],[136,34],[186,2],[126,25],[176,28],[112,38],
[169,9],[171,36],[116,25],[196,25]]
Y = ['Man','Woman','Woman','Man','Woman','Man','Woman','Man','Woman',
'Man','Woman','Man','Woman','Woman','Woman','Man','Woman','Woman','Man']
data_feature_names = ['height','length of hair']
X_train, X_test, Y_train, Y_test = cross_validation.train_test_split
(X, Y, test_size=0.40, random_state=5)
Sau khi cung cấp tập dữ liệu, chúng ta cần điều chỉnh mô hình có thể được thực hiện như sau
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,Y)
Dự đoán có thể được thực hiện với sự trợ giúp của mã Python sau
prediction = clf.predict([[133,37]])
print(prediction)
Chúng ta có thể hình dung cây quyết định với sự trợ giúp của mã Python sau
dot_data = tree.export_graphviz(clf,feature_names = data_feature_names,
out_file = None,filled = True,rounded = True)
graph = pydotplus.graph_from_dot_data(dot_data)
colors = ('orange', 'yellow')
edges = collections.defaultdict(list)
for edge in graph.get_edge_list():
edges[edge.get_source()].append(int(edge.get_destination()))
for edge in edges: edges[edge].sort()
for i in range(2):dest = graph.get_node(str(edges[edge][i]))[0]
dest.set_fillcolor(colors[i])
graph.write_png('Decisiontree16.png')
Nó sẽ đưa ra dự đoán cho đoạn mã trên là [‘Woman’] và tạo cây quyết định sau

Chúng ta có thể thay đổi giá trị của các tính năng trong dự đoán để kiểm tra nó.
Trình phân loại rừng ngẫu nhiên
Như chúng ta biết rằng các phương pháp tập hợp là các phương pháp kết hợp các mô hình học máy thành một mô hình học máy mạnh mẽ hơn. Random Forest, một tập hợp các cây quyết định, là một trong số đó. Nó tốt hơn cây quyết định duy nhất bởi vì trong khi vẫn giữ được khả năng dự đoán, nó có thể giảm hiện tượng khớp quá mức bằng cách lấy trung bình các kết quả. Ở đây, chúng tôi sẽ triển khai mô hình rừng ngẫu nhiên trên bộ dữ liệu ung thư scikit learn. Nhập các gói cần thiết
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
import matplotlib.pyplot as plt
import numpy as np
Bây giờ, chúng tôi cần cung cấp tập dữ liệu có thể được thực hiện như sau & trừ
cancer = load_breast_cancer()
X_train, X_test, y_train,
y_test = train_test_split(cancer.data, cancer.target, random_state = 0)
Sau khi cung cấp tập dữ liệu, chúng ta cần điều chỉnh mô hình có thể được thực hiện như sau
forest = RandomForestClassifier(n_estimators = 50, random_state = 0)
forest.fit(X_train,y_train)
Bây giờ, hãy lấy độ chính xác của tập con huấn luyện cũng như kiểm tra: nếu chúng ta tăng số lượng ước tính thì độ chính xác của tập con kiểm tra cũng sẽ tăng lên.
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_train,y_train)))
print('Accuracy on the training subset:(:.3f)',format(forest.score(X_test,y_test)))
đầu ra
Accuracy on the training subset:(:.3f) 1.0
Accuracy on the training subset:(:.3f) 0.965034965034965
Bây giờ, giống như cây quyết định, rừng ngẫu nhiên có mô-đun feature_importance sẽ cung cấp chế độ xem tốt hơn về trọng số của tính năng so với cây quyết định. Nó có thể được vẽ và hình dung như sau
n_features = cancer.data.shape[1]
plt.barh(range(n_features),forest.feature_importances_, align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()

Hiệu suất của một bộ phân loại
Sau khi triển khai thuật toán học máy, chúng ta cần tìm hiểu mức độ hiệu quả của mô hình. Các tiêu chí để đo lường hiệu quả có thể dựa trên bộ dữ liệu và số liệu. Để đánh giá các thuật toán học máy khác nhau, chúng ta có thể sử dụng các chỉ số hiệu suất khác nhau. Ví dụ: giả sử nếu bộ phân loại được sử dụng để phân biệt giữa các hình ảnh của các đối tượng khác nhau, thì chúng ta có thể sử dụng các chỉ số hiệu suất phân loại như độ chính xác trung bình, AUC, v.v. Theo một nghĩa nào đó, chỉ số chúng ta chọn để đánh giá mô hình học máy của mình là rất quan trọng vì việc lựa chọn chỉ số ảnh hưởng đến cách đo lường và so sánh hiệu suất của thuật toán máy học. Sau đây là một số số liệu –
Ma trận hỗn loạn
Về cơ bản, nó được sử dụng cho bài toán phân loại trong đó đầu ra có thể thuộc hai loại lớp trở lên. Đây là cách dễ nhất để đo lường hiệu suất của một bộ phân loại. Ma trận nhầm lẫn về cơ bản là một bảng có hai thứ nguyên là “Thực tế” và “Dự đoán”. Cả hai thứ nguyên đều có “Kết quả xác thực đúng (TP)”, “Phủ định đúng (TN)”, “Kết quả xác thực sai (FP)”, “Phủ định sai (FN)”.

Trong ma trận nhầm lẫn ở trên, 1 dành cho lớp tích cực và 0 dành cho lớp phủ định.
Sau đây là các thuật ngữ liên quan đến Ma trận nhầm lẫn –
- True positives – TP là các trường hợp khi loại điểm dữ liệu thực tế là 1 và dự đoán cũng là 1.
- Phủ định thực sự – TN là trường hợp khi lớp thực tế của điểm dữ liệu là 0 và dự đoán cũng là 0.
- Kết quả dương tính giả − FP là trường hợp khi loại điểm dữ liệu thực tế là 0 và giá trị dự đoán cũng là 1.
- Phủ định sai − FN là trường hợp khi lớp thực tế của điểm dữ liệu là 1 và dự đoán cũng là 0.
Sự chính xác
Bản thân ma trận nhầm lẫn không phải là thước đo hiệu suất như vậy nhưng hầu như tất cả các ma trận hiệu suất đều dựa trên ma trận nhầm lẫn. Một trong số đó là độ chính xác. Trong các bài toán phân loại, nó có thể được định nghĩa là số dự đoán chính xác do mô hình đưa ra so với tất cả các loại dự đoán đã thực hiện. Công thức tính độ chính xác như sau –
$$Accuracy = \frac{TP+TN}{TP+FP+FN+TN}$$
Độ chính xác
Nó chủ yếu được sử dụng trong truy xuất tài liệu. Nó có thể được định nghĩa là có bao nhiêu tài liệu được trả lại là chính xác. Sau đây là công thức tính độ chính xác –
$$Precision = \frac{TP}{TP+FP}$$
Thu hồi hoặc Độ nhạy
Nó có thể được định nghĩa là có bao nhiêu điểm tích cực mà mô hình mang lại. Sau đây là công thức tính toán thu hồi/độ nhạy của mô hình –
$$Gọi lại = \frac{TP}{TP+FN}$$
độ đặc hiệu
Nó có thể được định nghĩa là có bao nhiêu tiêu cực mà mô hình trả về. Nó hoàn toàn ngược lại với thu hồi. Sau đây là công thức tính độ đặc hiệu của mô hình –
$$Specificity = \frac{TN}{TN+FP}$$
Vấn đề mất cân bằng lớp học
Mất cân bằng lớp là tình huống trong đó số lượng quan sát thuộc về một lớp thấp hơn đáng kể so với số lượng quan sát thuộc về các lớp khác. Ví dụ, vấn đề này nổi bật trong trường hợp chúng ta cần xác định các bệnh hiếm gặp, các giao dịch gian lận trong ngân hàng, v.v.
Ví dụ về các lớp mất cân bằng
Chúng ta hãy xem xét một ví dụ về bộ dữ liệu phát hiện gian lận để hiểu khái niệm về lớp không cân bằng
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
Giải pháp
Cân bằng hoạt động của các lớp như một giải pháp cho các lớp mất cân bằng. Mục tiêu chính của việc cân bằng các lớp học là tăng tần số của lớp thiểu số hoặc giảm tần số của lớp đa số. Sau đây là các cách tiếp cận để giải quyết vấn đề mất cân bằng các lớp –
Lấy mẫu lại
Lấy mẫu lại là một loạt các phương pháp được sử dụng để xây dựng lại các tập dữ liệu mẫu – cả tập huấn luyện và tập kiểm tra. Lấy mẫu lại được thực hiện để cải thiện độ chính xác của mô hình. Sau đây là một số kỹ thuật lấy mẫu lại –Lấy mẫu dưới mức ngẫu nhiên – Kỹ thuật này nhằm mục đích cân bằng phân phối lớp bằng cách loại bỏ ngẫu nhiên các ví dụ về lớp đa số. Điều này được thực hiện cho đến khi các thể hiện của lớp đa số và thiểu số được cân bằng.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
Trong trường hợp này, chúng tôi đang lấy 10% mẫu không thay thế từ các trường hợp không gian lận và sau đó kết hợp chúng với các trường hợp gian lận –
Các quan sát không gian lận sau khi lấy mẫu ngẫu nhiên = 10% của 4950 = 495
Tổng số quan sát sau khi kết hợp chúng với các quan sát gian lận = 50+495 = 545
Do đó, hiện tại, tỷ lệ sự kiện cho tập dữ liệu mới sau khi lấy mẫu = 9%
Ưu điểm chính của kỹ thuật này là nó có thể giảm thời gian chạy và cải thiện khả năng lưu trữ. Nhưng mặt khác, nó có thể loại bỏ thông tin hữu ích trong khi giảm số lượng mẫu dữ liệu huấn luyện.Lấy mẫu quá mức ngẫu nhiên – Kỹ thuật này nhằm mục đích cân bằng phân phối lớp bằng cách tăng số lượng phiên bản trong lớp thiểu số bằng cách sao chép chúng.
Total observations = 5000
Fraudulent Observations = 50
Non-Fraudulent Observations = 4950
Event Rate = 1%
Trong trường hợp chúng tôi đang sao chép 50 quan sát gian lận 30 lần thì các quan sát gian lận sau khi sao chép các quan sát thuộc nhóm thiểu số sẽ là 1500. Và khi đó, tổng số quan sát trong dữ liệu mới sau khi lấy mẫu quá mức sẽ là 4950+1500 = 6450. Do đó, tỷ lệ sự kiện cho tập dữ liệu mới sẽ là 1500/6450 = 23%.
Ưu điểm chính của phương pháp này là sẽ không làm mất thông tin hữu ích. Nhưng mặt khác, nó có nhiều khả năng khớp quá mức vì nó sao chép các sự kiện của lớp thiểu số.
Gói kỹ thuật
Phương pháp này về cơ bản được sử dụng để sửa đổi các thuật toán phân loại hiện có để làm cho chúng phù hợp với các tập dữ liệu không cân bằng. Theo cách tiếp cận này, chúng tôi xây dựng một số bộ phân loại hai giai đoạn từ dữ liệu gốc và sau đó tổng hợp các dự đoán của chúng. Bộ phân loại rừng ngẫu nhiên là một ví dụ về bộ phân loại dựa trên tập hợp.
Xem thêm : AI với Python – Học có giám sát: Hồi quy